INTRODUCTION
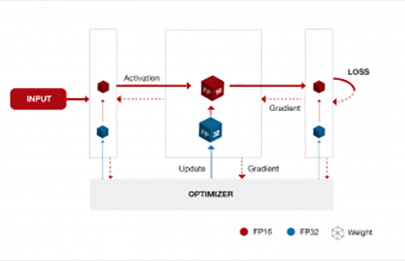
Our deep learning research and product development benefits from increases when larger networks become trained with more data on powerful parallel hardware. Our HPC (High Performance Computing) team will enable AI to continue scaling with trends in computation. Over the next two to three years, up to 100x speedups will be possible from improved hardware, but the cost of data movement is rising relative to the cost of computation. Therefore, new software and training techniques are necessary to realize these improvements. Advancements in the training performance of deep learning algorithms will come from three directions: (1) scaling up performance on individual processors, (2) scaling out to multiple processors, (3) reducing the computation required for training. Our team investigates these aspects in partnership with SVAIL research teams and Baidu DL practitioners that require large-scale computation.